第一二三范式怎么區分
瀏覽量: 次 發布日期:2024-02-06 04:17:03
第一二三范式怎么區分

一、概述
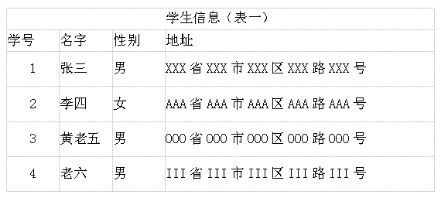
數據庫范式是關系型數據庫設計的基礎理論,其目的是確保數據的完整性和減少數據冗余。在關系型數據庫設計中,通常需要滿足一定的范式要求,以確保數據表的結構合理、數據一致性和完整性。常見的范式有第一范式(1F)、第二范式(2F)和第三范式(3F)。
二、特點對比

1. 第一范式(1F)
第一范式是最基本的范式要求,它要求數據表中的每一列都是不可分割的最小單元,即原子性。也就是說,每個字段只能包含一個值,不能包含另一個數據表。第一范式的目的是確保數據的完整性和減少數據冗余。
2. 第二范式(2F)
第二范式是在第一范式的基礎上進一步規范化數據表的結構。它要求數據表中的所有非主鍵字段都完全依賴于主鍵,不能只依賴于主鍵的一部分。換句話說,如果一個數據表的主鍵是復合主鍵,那么非主鍵字段必須依賴于整個復合主鍵,而不能只依賴于復合主鍵中的某一個部分。第二范式的目的是進一步減少數據冗余和確保數據的完整性。
3. 第三范式(3F)
第三范式是在第二范式的基礎上進一步規范化數據表的結構。它要求數據表中的所有非主鍵字段必須直接依賴于主鍵,不能間接依賴于主鍵。換句話說,如果一個數據表中的某個字段既不是主鍵也不是其他非主鍵字段的函數,那么這個字段就是冗余的,應該被刪除或者轉移到其他數據表中。第三范式的目的是消除冗余數據,減少數據庫的大小和提高查詢效率。
三、應用場景
在實際的數據庫設計中,應該根據具體的業務需求和應用場景來選擇合適的范式級別。通常情況下,為了確保數據的完整性和減少數據冗余,應該盡可能地滿足更高的范式級別。但是,過度地規范化數據庫結構也會導致數據操作變得復雜和繁瑣,因此需要在規范化和操作簡便性之間進行權衡。在某些情況下,為了提高查詢效率和應用性能,可以適當放寬范式要求,進行反規范化設計。總之,合理地設計數據庫結構是關系型數據庫設計的重要任務之一。





 QQ客服
QQ客服