分布式數(shù)據(jù)源有哪些
瀏覽量: 次 發(fā)布日期:2024-11-30 09:29:30
標(biāo)簽

分布式數(shù)據(jù)源是指將數(shù)據(jù)分散存儲(chǔ)在多個(gè)節(jié)點(diǎn)上,通過分布式計(jì)算框架進(jìn)行數(shù)據(jù)處理的系統(tǒng)。它能夠有效提高數(shù)據(jù)處理的性能、擴(kuò)展性和容錯(cuò)性。
分布式數(shù)據(jù)源的優(yōu)勢(shì)標(biāo)簽
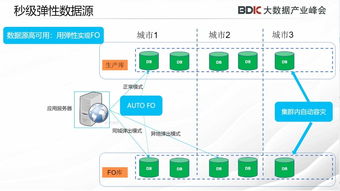
1. 高性能:分布式數(shù)據(jù)源能夠并行處理數(shù)據(jù),顯著提高數(shù)據(jù)處理速度。
2. 高擴(kuò)展性:隨著數(shù)據(jù)量的增長(zhǎng),分布式數(shù)據(jù)源可以輕松擴(kuò)展,滿足不斷增長(zhǎng)的數(shù)據(jù)處理需求。
3. 高可用性:分布式數(shù)據(jù)源通過數(shù)據(jù)冗余和故障轉(zhuǎn)移機(jī)制,確保系統(tǒng)的高可用性。
常見分布式數(shù)據(jù)源架構(gòu) 分布式數(shù)據(jù)庫標(biāo)簽
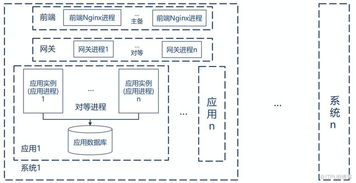
分布式數(shù)據(jù)庫如Apache Cassadra、Amazo DyamoDB等,通過數(shù)據(jù)分片和復(fù)制機(jī)制實(shí)現(xiàn)數(shù)據(jù)的分布式存儲(chǔ)。
分布式文件系統(tǒng)標(biāo)簽
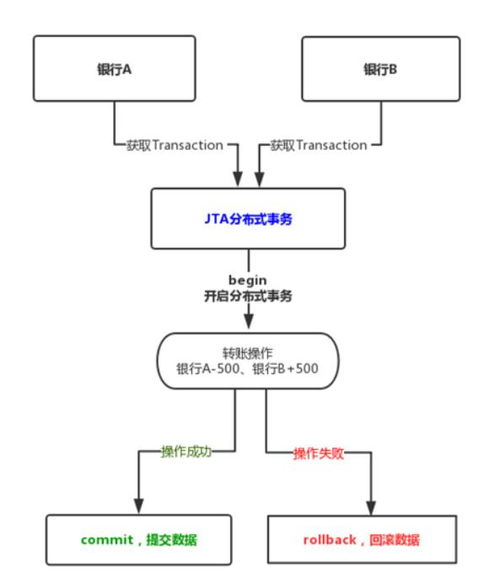
分布式文件系統(tǒng)如Hadoop HDFS、Alluxio等,提供大規(guī)模數(shù)據(jù)存儲(chǔ)和訪問能力。
分布式計(jì)算框架標(biāo)簽
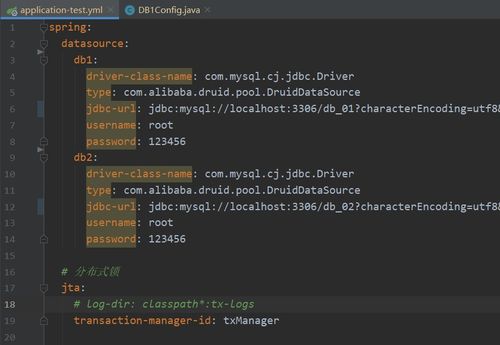
分布式計(jì)算框架如Apache Spark、Apache Flik等,支持批處理、流處理和實(shí)時(shí)計(jì)算。
分布式數(shù)據(jù)源在實(shí)際應(yīng)用中的挑戰(zhàn) 數(shù)據(jù)一致性問題標(biāo)簽
在分布式數(shù)據(jù)源中,數(shù)據(jù)一致性問題是一個(gè)常見挑戰(zhàn)。需要采用分布式鎖、事務(wù)管理等機(jī)制來保證數(shù)據(jù)一致性。
數(shù)據(jù)分區(qū)和負(fù)載均衡標(biāo)簽
數(shù)據(jù)分區(qū)和負(fù)載均衡是分布式數(shù)據(jù)源的關(guān)鍵技術(shù)。合理的數(shù)據(jù)分區(qū)和負(fù)載均衡策略能夠提高系統(tǒng)性能和可擴(kuò)展性。
容錯(cuò)和故障轉(zhuǎn)移標(biāo)簽
分布式數(shù)據(jù)源需要具備容錯(cuò)和故障轉(zhuǎn)移能力,以應(yīng)對(duì)節(jié)點(diǎn)故障和數(shù)據(jù)丟失等問題。
解決方案與最佳實(shí)踐 分布式鎖標(biāo)簽
分布式鎖可以保證在分布式環(huán)境中對(duì)共享資源的訪問互斥性。常見的分布式鎖實(shí)現(xiàn)包括基于Zookeeper、Redis等。
數(shù)據(jù)分區(qū)策略標(biāo)簽
合理的數(shù)據(jù)分區(qū)策略能夠提高數(shù)據(jù)處理的并行度和系統(tǒng)性能。常見的分區(qū)策略包括范圍分區(qū)、哈希分區(qū)等。
負(fù)載均衡標(biāo)簽
負(fù)載均衡技術(shù)可以將請(qǐng)求均勻分配到各個(gè)節(jié)點(diǎn),提高系統(tǒng)吞吐量和可用性。常見的負(fù)載均衡算法包括輪詢、最少連接數(shù)等。
分布式數(shù)據(jù)源在提高數(shù)據(jù)處理性能、擴(kuò)展性和可用性方面發(fā)揮著重要作用。通過深入了解分布式數(shù)據(jù)源的概念、架構(gòu)和挑戰(zhàn),企業(yè)可以構(gòu)建高效、可靠的數(shù)據(jù)處理平臺(tái),滿足日益增長(zhǎng)的數(shù)據(jù)處理需求。 關(guān)鍵詞分布式數(shù)據(jù)源、分布式數(shù)據(jù)庫、分布式文件系統(tǒng)、分布式計(jì)算框架、數(shù)據(jù)一致性、數(shù)據(jù)分區(qū)、負(fù)載均衡、容錯(cuò)、故障轉(zhuǎn)移. 硬盤數(shù)據(jù)真的能恢復(fù)嗎,揭秘?cái)?shù)據(jù)丟失后的恢復(fù)可能性與實(shí)際操作
. 磁盤陣列維修找哪家,專業(yè)數(shù)據(jù)恢復(fù)機(jī)構(gòu)推薦指南
. deepcreased,自動(dòng)化內(nèi)容生成與知識(shí)庫構(gòu)建指南
. v3700更換控制器后,虛擬機(jī)虛擬機(jī)讀取不到原來的存儲(chǔ)器,V3700控制器更換后虛擬
. 北京硬盤數(shù)據(jù)恢復(fù)設(shè)備,專業(yè)解決方案與選擇指南
. 電腦硬盤數(shù)據(jù)恢復(fù)軟件哪個(gè)好用一點(diǎn),盤點(diǎn)好用工具,助您找回珍貴數(shù)據(jù)
. 移動(dòng)硬盤維修貴嗎,價(jià)格因素與預(yù)算建議
. v3500恢復(fù)出廠設(shè)置,V3500設(shè)備一鍵恢復(fù)出廠設(shè)置操作指南
. 武漢 哪里恢復(fù)硬盤數(shù)據(jù),專業(yè)機(jī)構(gòu)與解決方案一覽
. 硬盤數(shù)據(jù)恢復(fù)需要多久,硬盤數(shù)據(jù)恢復(fù)時(shí)間概述
. 長(zhǎng)春固態(tài)硬盤數(shù)據(jù)恢復(fù),專業(yè)服務(wù),數(shù)據(jù)無憂
. 硬盤恢復(fù)數(shù)據(jù)后文件打不開了怎么辦,硬盤數(shù)據(jù)恢復(fù)后文件無法打開的解決攻略
. emc存儲(chǔ)硬盤壞了2塊更換步驟,EMC存儲(chǔ)系統(tǒng)雙硬盤故障更換操作指南
. 1t硬盤數(shù)據(jù)恢復(fù)多少錢,不同情況下的成本分析
. 硬盤壞了影響內(nèi)存嗎知乎,硬盤損壞對(duì)內(nèi)存使用的影響概述
. 硬盤raid1,數(shù)據(jù)鏡像備份,保障數(shù)據(jù)安全與系統(tǒng)穩(wěn)定
. oracle刪除的數(shù)據(jù)怎么恢復(fù),Oracle數(shù)據(jù)庫刪除數(shù)據(jù)恢復(fù)方法詳解
. 硬盤數(shù)據(jù)恢復(fù)1400,專業(yè)軟件與服務(wù)推薦
. 壽光硬盤數(shù)據(jù)恢復(fù),專業(yè)服務(wù),守護(hù)您的數(shù)據(jù)安全
. 杭州硬盤數(shù)據(jù)恢復(fù)方法,專業(yè)技術(shù)助力數(shù)據(jù)失而復(fù)得





 QQ客服
QQ客服